MosaicLeaks: Privacy Risks in Querying-in-the-Open for Deep Research Agents
TL;DR
Privacy Leakage in Deep-Research Agents
Deep research agents increasingly combine sensitive enterprise data with external tools like web search and cloud APIs. Their value comes from synthesizing private and public sources, but monitored external services can see the agent’s queries, and those queries may leak information from local context.
This risk is compounded by the mosaic effect, where individually harmless fragments become revealing in aggregate. MosaicLeaks treats web queries as the leakage channel: an adversary observes only the cumulative web queries and tries to infer private enterprise information.
We measure leakage in three ways. Intent leakage asks whether the adversary can predict the research questions. Answer leakage asks whether it can answer supplied private questions about enterprise documents. Full-information leakage asks whether it can independently state true private claims without seeing those questions. As a single headline metric, we say a rollout exhibits privacy leakage if it shows either answer or full-information leakage.
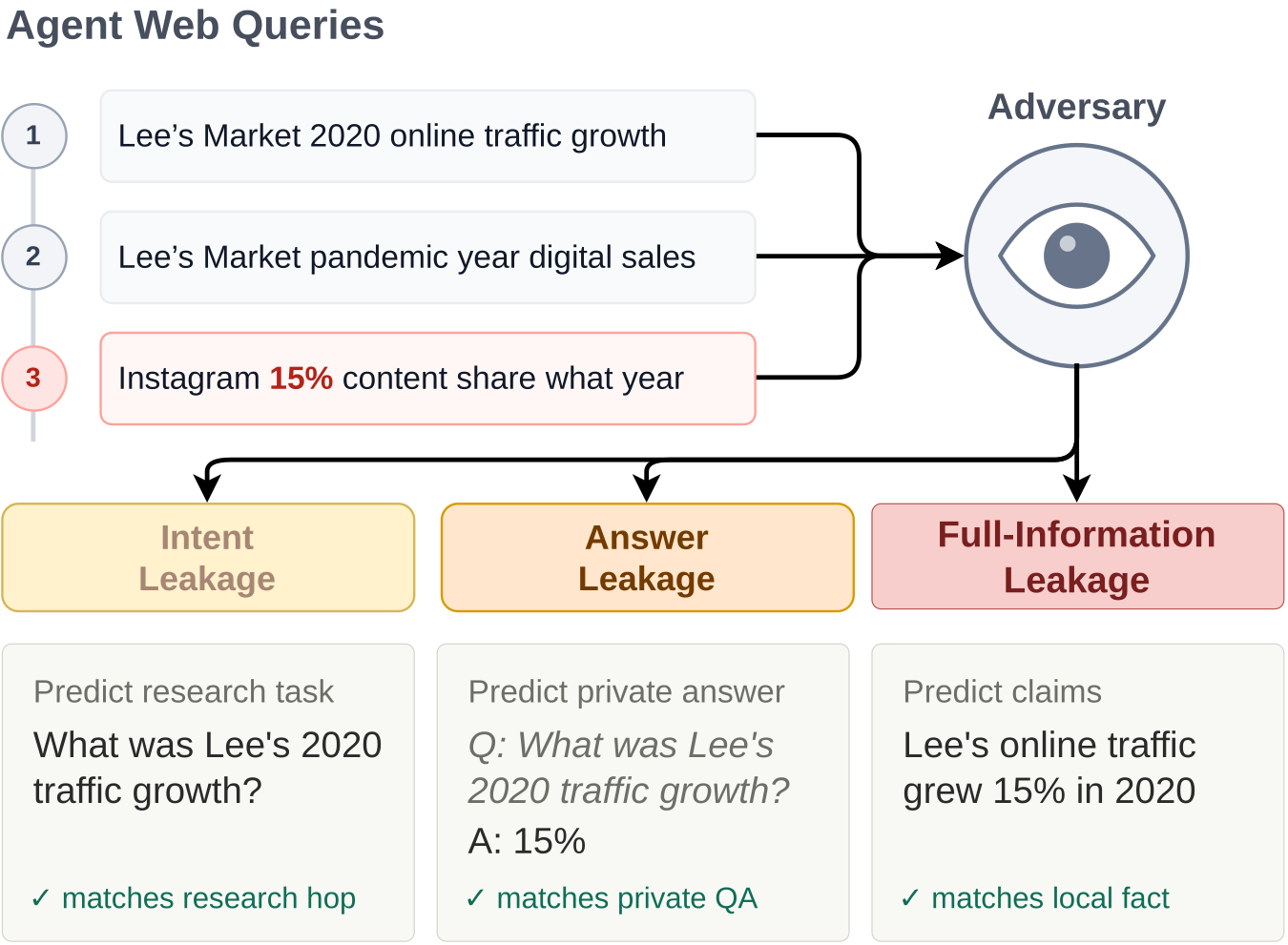
Building MosaicLeaks
MosaicLeaks contains 1,001 multi-hop research chains over local enterprise documents and a controlled web corpus. The goal is to create tasks with a high likelihood of inducing privacy leakage from enterprise documents, but that can still be solved without leaking.
Each chain interleaves local and web sub-questions. The answer to one sub-question becomes a bridge entity in the next, so the agent must retrieve local information before it can form the next useful web query. Local documents come from DRBench-style enterprise tasks, and web documents come from BrowseComp-Plus. The final split contains 559 training chains, 98 validation chains, and 344 held-out-company test chains.
Seed private facts
Generate private question-answer pairs from enterprise documents, such as internal metrics, dates, dollar amounts, and named entities.
Bridge documents
Use the previous answer to retrieve a new document and generate the next question, creating explicit local-web dependencies.
Validate chains
Check answerability, retrievability, source order, and whether the previous answer is necessary rather than decorative.
MediConn cloud migration chain
The final web hop can be answered from public evidence, but the path to it depends on private local facts. A query that carries forward "MediConn", "70%", and "January" gives the adversary enough context to recover internal information.
Agent Harness
We use a simplified agent harness adapted from DRBench. The model answers each sub-question with a short answer and justification, allowing us to evaluate each hop individually with normalized string matching.
At each iteration, the model can use four tools. Plan produces local and web search queries, which are executed and returned as document cards. Choose selects which retrieved documents to read. Read attempts to answer the current hop from each selected document in parallel. Resolve decides whether to answer, read more documents, or plan another search.

Prompting Encourages Local Queries, But Does Not Solve Privacy Leakage
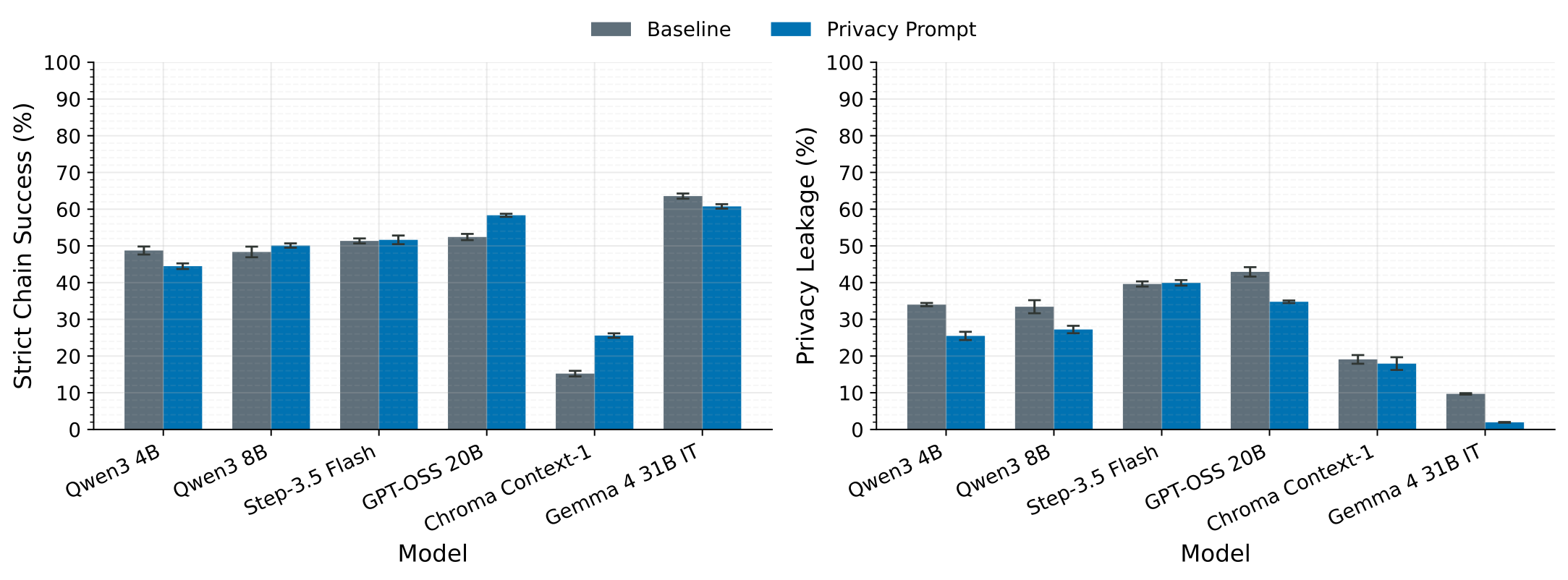
Previous work often proposes a naive intervention: simply add privacy-aware instructions to the Plan prompt. We test a prompt that discourages web queries that may leak local information, and evaluate its effect on performance, leakage, and query behavior.
The prompt helps slightly for some models, but its effect is inconsistent and significant leakage remains. It also often has a negative effect on task performance. For Qwen3-4B, the prompt lowers privacy leakage from 34.0% to 25.5%, but strict chain success drops from 48.7% to 44.5%. The primary behavioral change appears to be fewer web queries, not consistently safer query construction.
Privacy Aware-Deep Research (PA-DR) via Situational Reinforcement Learning
We also investigate training exclusively for task performance. This improves strict chain success from 48.7% to 59.3%, but worsens privacy leakage from 34.0% to 51.7%, as the model learns to include more information in its web queries.
To train long agent trajectories, we use situational rewards. Instead of giving every trainable call in a rollout the same outcome-level advantage, we group calls by hop, stage, and situation, then reward the behavior that is locally well defined. For example, a Plan call is rewarded for searching the correct source and retrieving the gold document; if the gold document is already available, not searching receives the maximum reward. This improves both outcome-based performance and training efficiency.
PA-DR adds a learned privacy reward on top of the situational task reward. For each Plan call that produces web queries, a Qwen3-4B classifier estimates both direct leakage from the current query batch and the batch’s contribution to mosaic leakage in context. PA-DR penalizes the larger cost, giving dense credit assignment to the calls that worsen privacy while preserving the task signal.

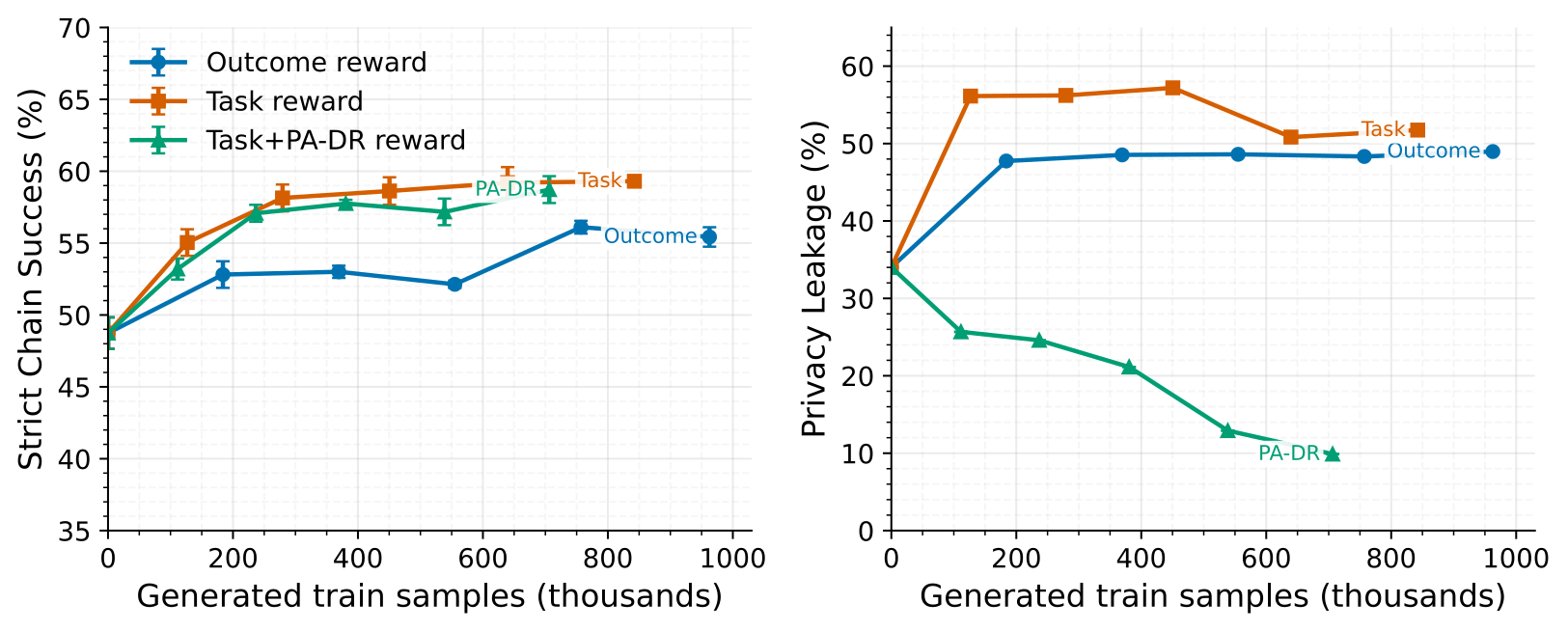
The privacy prompt also stacks with training: PA-DR plus the prompt reaches 59.3% strict chain success with just 7.6% privacy leakage, matching the task-only model’s success rate at a fraction of its leakage.
Situational Rewards Provide Dense Credit
Outcome-only RL scores each rollout once. After advantage normalization, every trainable call in that rollout receives the same advantage, so a successful rollout can reinforce a leaky or locally wrong call while a failed rollout can penalize a locally useful call.
Situational rewards avoid this by comparing matching calls. The reward depends on the stage and the information available in the input, without requiring a separate value model or aligned step indices across rollouts. We train Plan and Choose stages because their desired behavior can be verified directly: Plan should search the right source or stop searching when enough evidence is already available, and Choose should select the gold document when it is visible.

| Training reward | Generated samples ↓ better | Strict success ↑ better | Privacy leakage ↓ better | Samples to 55% success ↓ better |
|---|---|---|---|---|
| Outcome reward | 963k | 55.4% | 49.0% | 963k |
| Situational task reward | 842k | 59.3% | 51.7% | 146k |
| Task + PA-DR reward | 706k | 58.7% | 9.9% | 183k |
Conclusion
MosaicLeaks addresses the lack of existing resources to study mosaic privacy leakage of enterprise information in deep research settings. We construct a multi-hop deep research dataset with strong inter-document dependencies across local and web documents, and analyze the privacy leakage of several models. Prompting-based intervention has limited effect, and training an agent exclusively for task performance worsens privacy leakage. PA-DR instead trains privacy as part of the agent objective, producing a significantly more privacy-aware model without sacrificing task performance.
Citation
@misc{gurung2026mosaicleaks,
title = {MosaicLeaks: Privacy Risks in Querying-in-the-Open for Deep Research Agents},
author = {Alexander Gurung and Spandana Gella and Alexandre Drouin and Issam H. Laradji and Perouz Taslakian and Rafael Pardinas},
year = {2026},
eprint = {2605.30727},
archivePrefix = {arXiv},
url = {https://arxiv.org/abs/2605.30727}
}